 Reading Time: 3 minutes
Reading Time: 3 minutesAnalytics workloads in Decision Intelligence products and the need to optimize them
Decision Intelligence products help businesses make timely decisions that are accountable and actionable, with accurate inferences and recommendations. Decision Intelligence platforms need to offer key features that enable users to perform prescriptive, predictive, diagnostic, and descriptive analyses. Since theserequirecompute-intense processing, it is critical for us to minimize latency, maximize speed, and manage the scale of any additional data analytics workload on these DI platforms.
In this blog, we discuss the challenges of conventional ML workflows and how we can leverage a Cloud-based ML workflow to overcome these challenges.
As an enthusiast for data & amp; insights, and with my experience in curating critical engineering features for Lumin- a leading Decision Intelligence product, I believe I can offer a unique perspective on how a Cloud-based ML workflow is a better option than conventional ML workflows.
Machine Learning (ML) workflow: Conventional and run of the mill
The conventional machine learning workflows(See Fig. 1) fetch the data out of the storage layer, pre-process it, run it through the training models and finally save the model in a Cloud storage like S3.
This process has two major drawbacks:
- High costs: Having a separate compute infrastructure from the data eventually increases maintenance costs in the long run.
- Security: Moving the data out of the secured storage layer, leaves it potentially decrypted and vulnerable to attacks.
Alternatively, the computations can be processed where the data lives with Python, Java, and Scala code natively in Snowflake, ensuring that all the workloads are handled without moving data outside of the governed boundary and eliminating exposure to security risks. This could reduce maintenance costs, ensure data security, and improve overall performance by not having to shuffle data across environments.
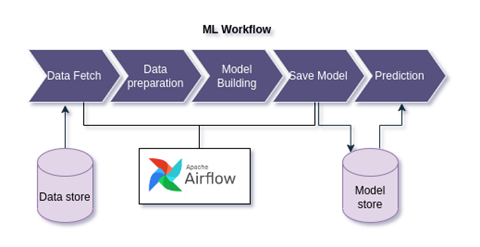
Figure 1: Conventional ML workflow
Paving the path for a Cloud-based ML workflow with Snowpark
Snowpark is a set of libraries and runtimes that securely enable developers to deploy and process Python code in Snowflake.
Familiar client-side libraries: Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages,which data practitioners like to use. It also includes the Snowpark ML library for faster and more intuitive end-to-end machine learning in Snowflake (See Figure 2). Snowpark ML has 2 APIs – Snowpark ML Modeling (public preview) for model development, and Snowpark ML Operations (private preview) for model deployment.
Flexible runtime constructs: Snowpark provides flexible runtime constructs that allow users to bring in and run custom logic. Developers can seamlessly build data pipelines, ML models, and data applications with User-Defined Functions (UDFs) and Stored Procedures (SPROCs). Developers can also leverage the embedded Anaconda repository for effortless access to thousands of pre-installed open-source libraries.
These capabilities allow data engineers, data scientists, and data developers to build pipelines, ML models,and applications faster and more securely on a single platform using their language of choice.
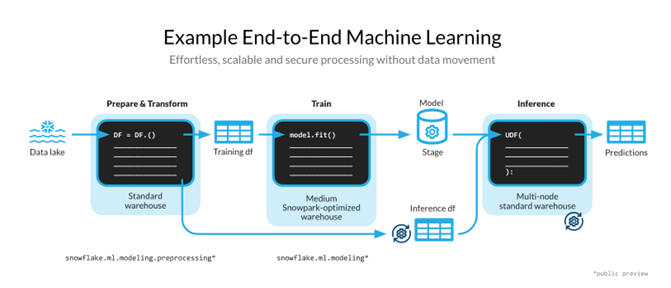
Figure 2: Machine Learning end-to-end workflow with Snowpark.
Snowpark code can be executed using two approaches(See Fig. 3):
- Data Frames: These APIs are pushed to Snowflake where they are executed in Snowflake’s elastic engine either as SQL query or more sophisticated UDFs automatically on behalf of the users.
- Python Functions: These can be creation of UDF/Stored Procedures, during which Snowpark serializes and uploads the code to a stage. While calling of UDF/Stored Procedures, Snowpark executes the function in the secure Python sandbox in the server-side runtime, where the data is located.Snowpark is also integrated with the Anaconda repository, which has access to thousands of curated, open-source Python packages.
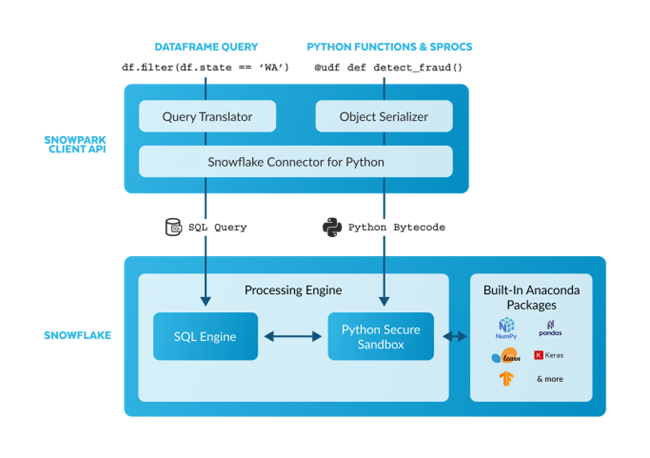
Figure 3: Snowpark approaches to code.
Let us look at some sample code for each of these approaches:
Dataframe API (Fig. 4) which can be used for data preparation and feature engineering.

Figure 4: Snowpark Dataframe API example
Stored Procedures(as illustrated in Figure 5) can be used for model training.
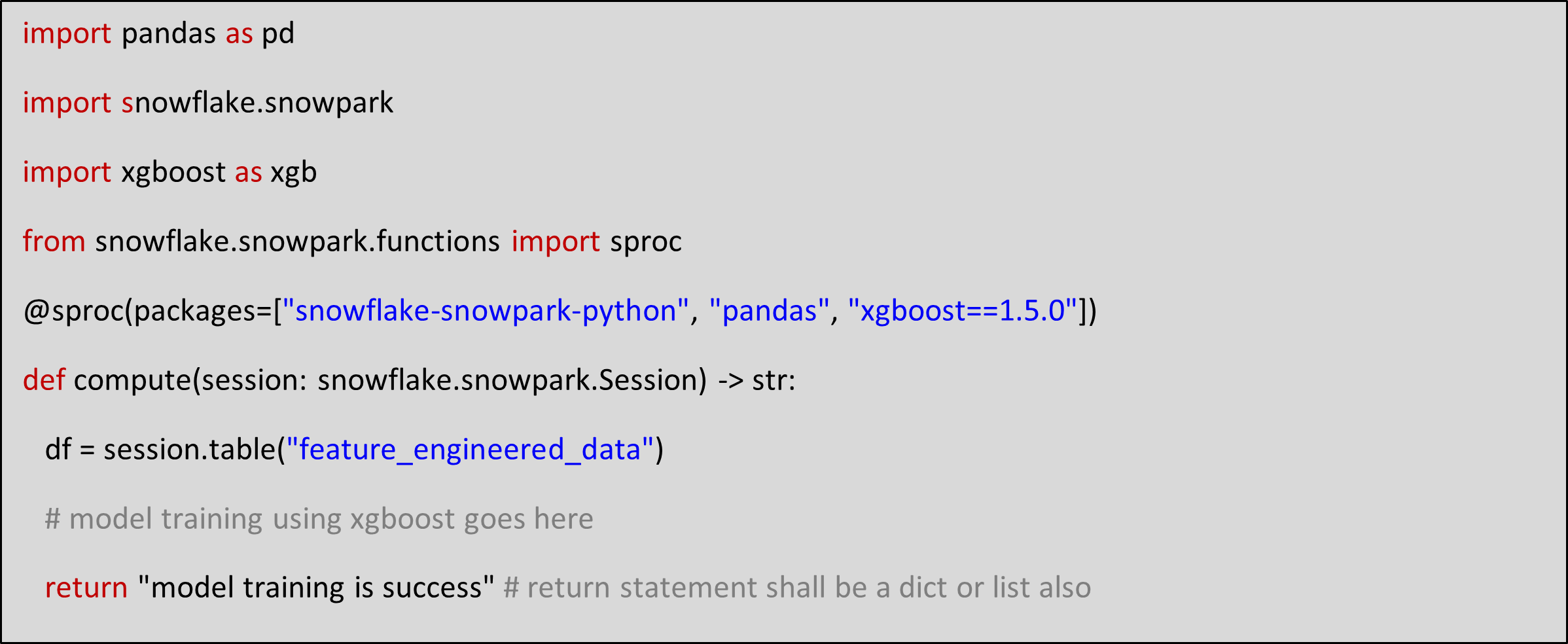
Figure 5: Snowpark stored procedure example
An example for Snowpark UDFs is illustrated below (Figure 6)

Figure 6: Snowpark UDF example
Now that we have seen how conventional ML and Cloud-based ML workflows function, here is a side-by-side comparison of both approaches.
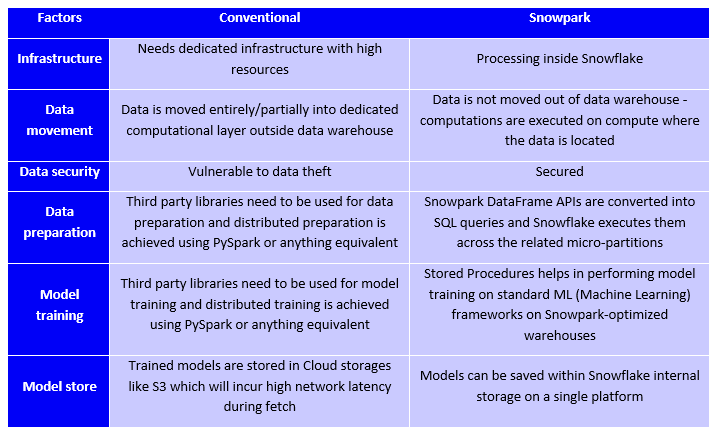
As you can see there is a clear advantage that a Cloud-based ML workflow offers businesses. Now let me show you a glimpse of how Lumin takes advantage of the power of the Cloud.
Lumin’s Declarative AI powered by Snowflake
Time series Forecasting is one of the more advanced features of Lumin and is in fact the prime showcase of Lumin’s Declarative AI capabilities.
Here’s how it works: Let’s assume a business user wants to see how the sales would look like with the current trend of business – the user can simply ask in plain English language, “What will be my sales in the next 6 months?”. Lumin’s intelligence layer understands this natural language, converts into Lumin query language and hands over to the Analytics core engine.
The analytics core engine (See Fig. 7) understands the requirement and configuration from the self-serve layer and executes the following steps to arrive at a final output.
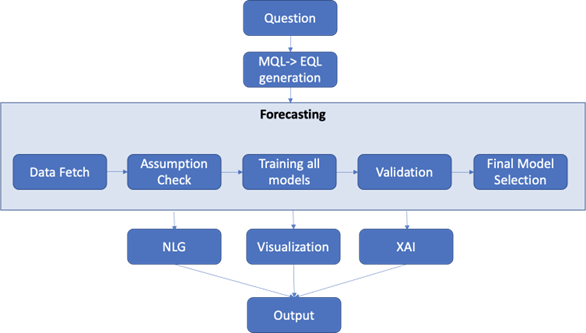
Figure 7: Analytics core engine workflow
Data preparation: In this step, the most common and essential preparation techniques like sanity checks, seasonality checks, stationary checks, missing values treatment, outlier removal, etcetera, will be performed.
Model training: Lumin’s forecasting engine leverages ensemble modeling technique to choose the best model given the data.
Hyperparameter tuning is done at this stage using Grid Search, and the champion model is selected by minimizing MAPE (Mean Absolute Percentage Error) value, and subsequently saved inside Snowflake’s internal stage in a pickled format. This entire training logic exists within Snowflake Data Warehouse in the form of stored procedures. The Snowpark client gets initialized with the analytic core engine for registering these stored procedures and invoking them with required inputs. Neither the data nor the model is transferred outside Snowflake’s infrastructure.
Model explanation and Narratives: Lumin along with the forecast view also provides the narratives and explains how it arrived at specific insights (See).
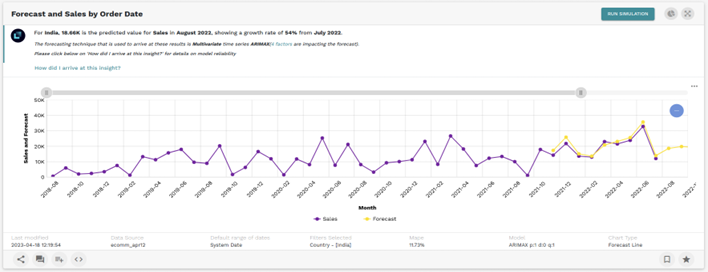
Figure 8: Model explanation
On the self-serve layer, creators can configure sales as the measure, and choose the machine learning technique(s) on which the forecasting needs to be performed, or simply set it to Auto mode.
Model Inference: Lumin enables user to simulate (See) and understand the impact on the measure by altering the exogenous factors. The updated values are passed to the Analytics core engine and used for inferencing. Here UDFs are used to fetch the saved model from Snowflake internal stage, execute the prediction within, and return the result to the application visualisation layer.
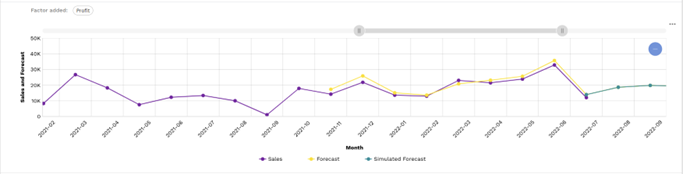
Figure 9: Run simulation.
Testing the firepower
As an engineering group, it is in our best interests to conduct thorough testing of the product features in terms of performance. We tested our features driven with Snowflake-Snowpark vs three different analytical workloads (PySpark, FastAPI based Microservices, and SQL logics), run on custom datasets and scenarios.
During these tests, we were able to observe that the Snowflake-Snowpark workflow yielded very good results. We observed that for the forecast workloads, which were converted from FastAPI based microservices to Snowpark SPROC, Lumin achieved a 20% improvement in speed of execution, and a 14% in cost savings. We also noticed that Lumin’s key driver analysis revealed a 90%-time benefit and a 12% cost benefit by transitioning from the previous Spark-based batch mode to the new Snowpark-based real-time run, which incorporates an algorithmic upgrade.
Subsequently, Nudges validation was converted from Spark to Snowflake SQL, which yielded a further ~80% improvement in speed of execution and a net cost savings of up to 65%.
It is also essential to note that conventional ML workflows have connected microservices and static clusters for execution, which increases the overall runtime and cost. Taking all this into consideration, we will be able to observe exponential benefits with Snowflake &; Snowpark, both in terms of cost and speed of execution.
References











