Reading Time: 4 minutes
Reading Time: 4 minutesQ: “How can I avoid constantly jumping between Snowflake UI and Spectra UI to know what transformations would be apt for this data pipeline I am trying to configure on Fosfor Spectra?”
Q: “How do I ensure that the pipelines I am developing are not affecting my production databases and still be able to see the results of my pipeline execution without writing to an actual table?”
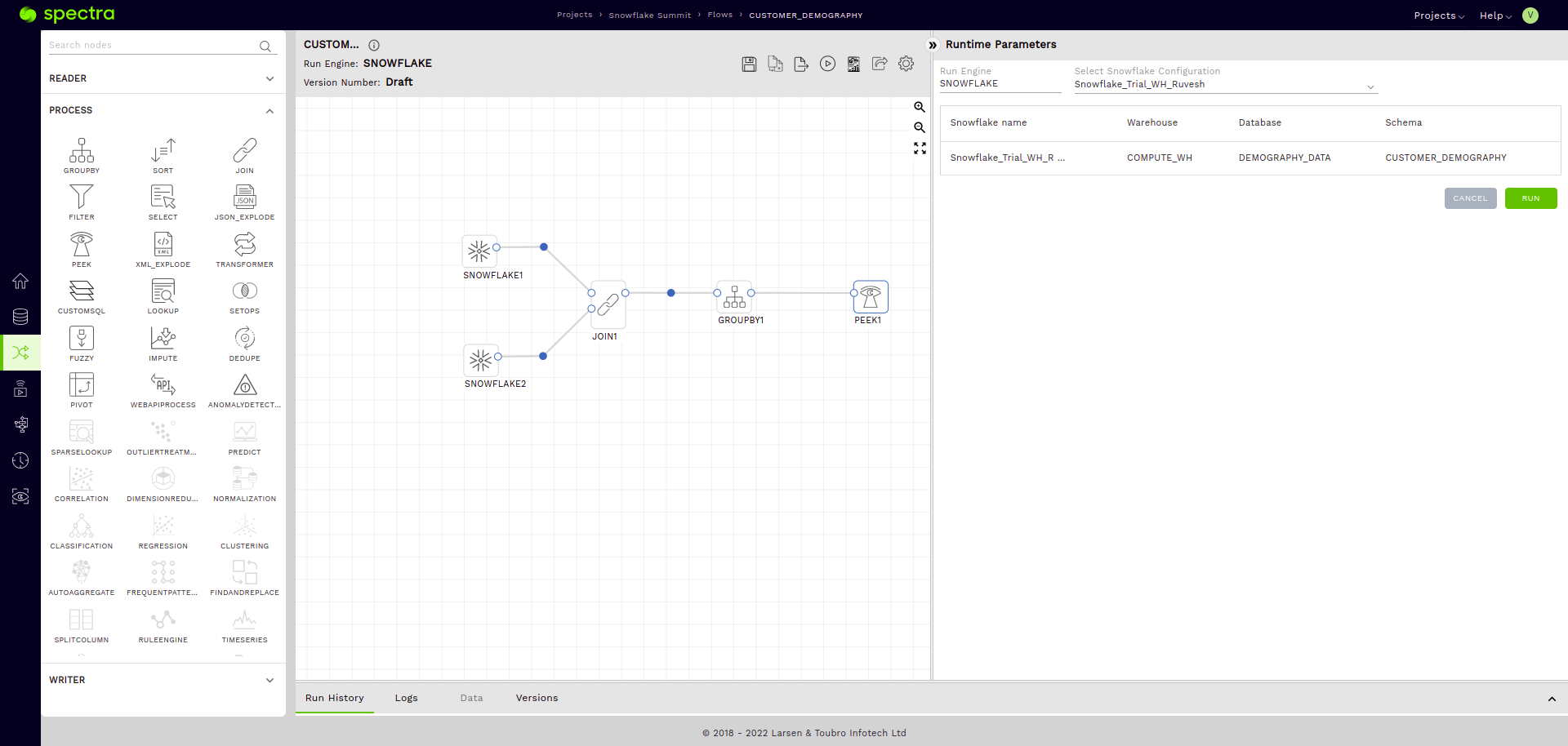
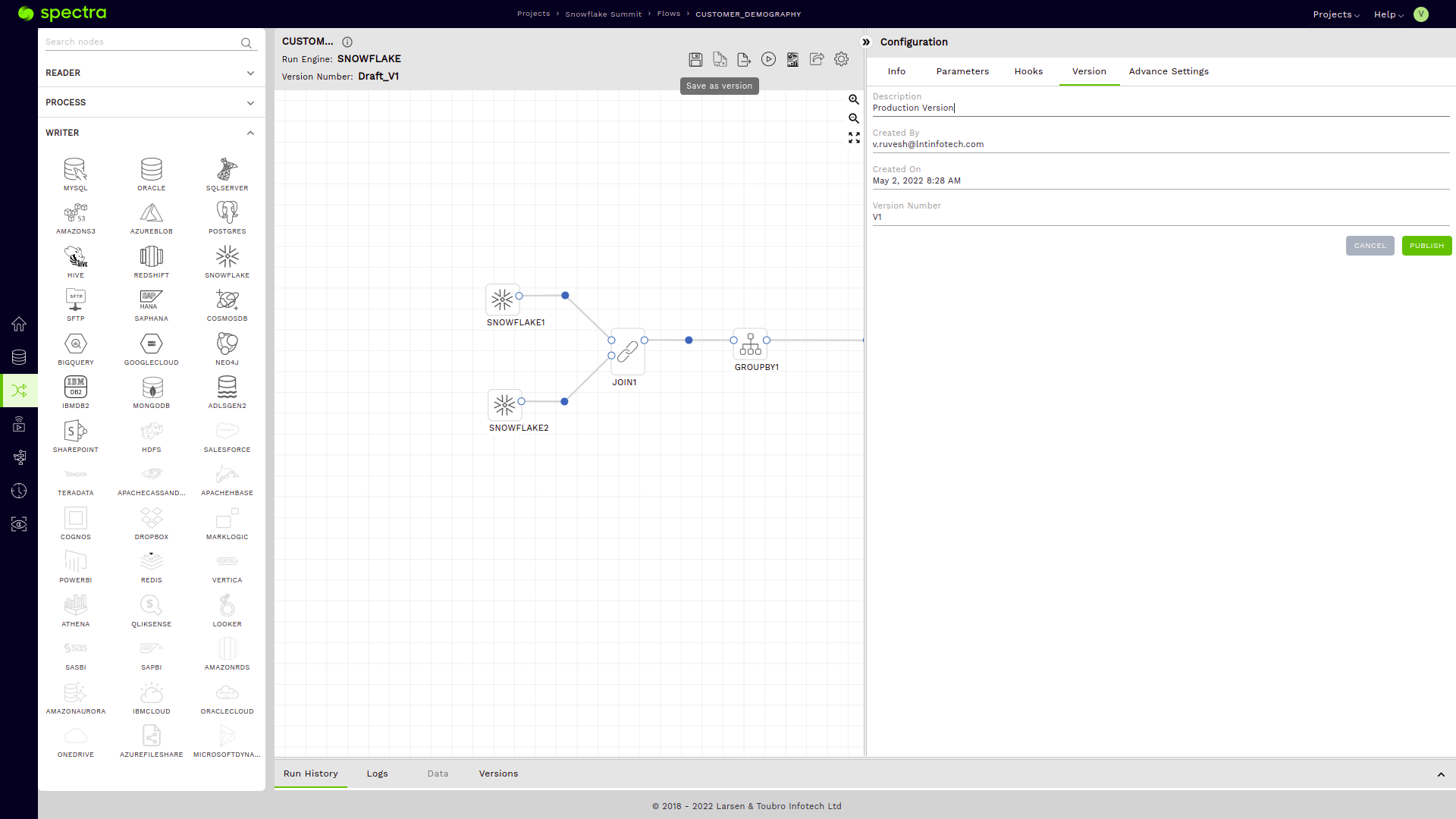
Q: “I am done with testing my pipeline. Now, I want to have a robust, production-ready version of my flow. How can I achieve this?”
When creating Snowflake data pipelines on Fosfor Spectra, these common questions come to mind. In this article, let’s find out how Spectra facilitates its users to construct their Snowflake pipelines, make them robust and ensure that they are production-ready.
We will cover the following topics in this article:
- Flow configuration and what nodes we will use.
- How to see sample data of tables in Fosfor Spectra.
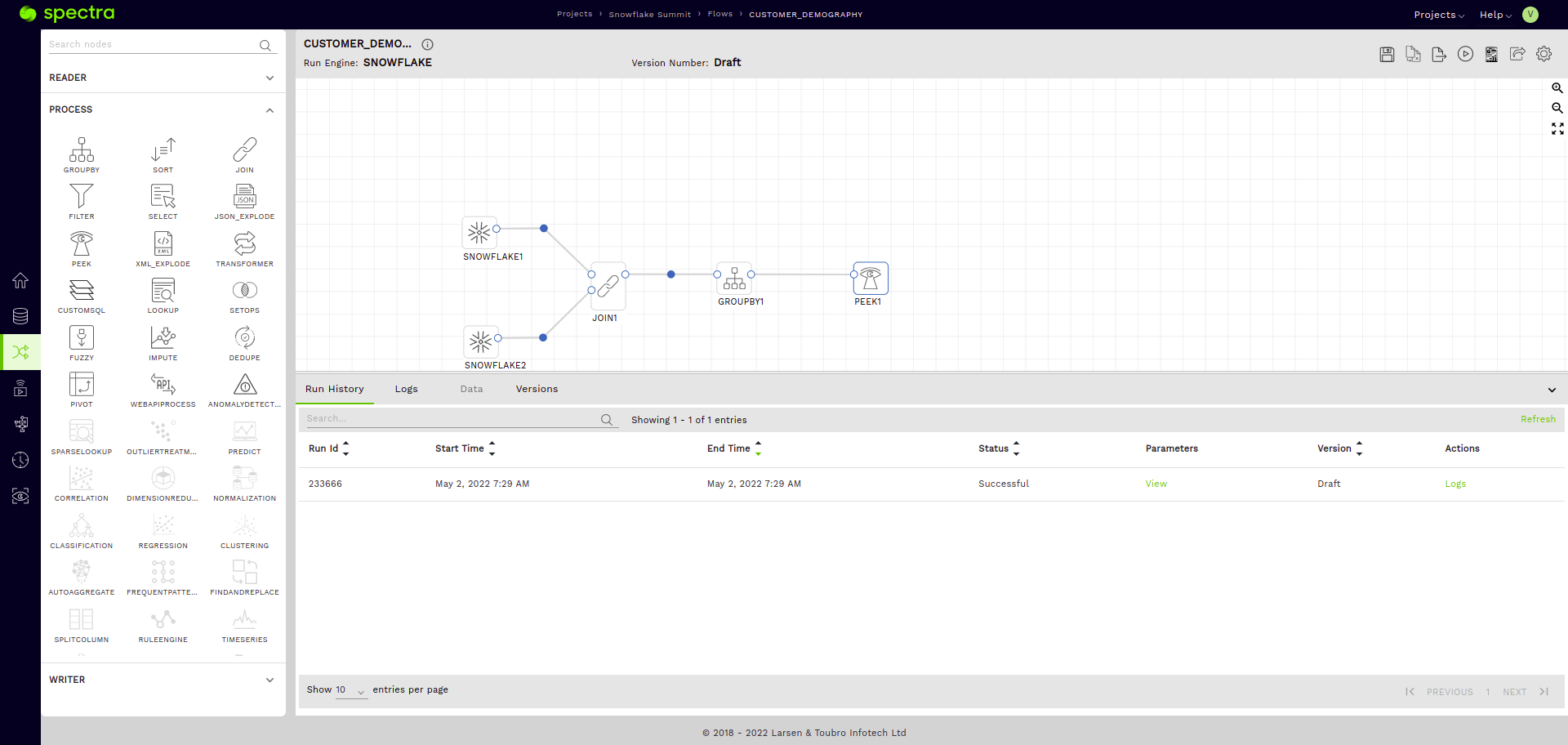
- Using the peek node to validate the output of our flow.
- Saving a production-ready version with an actual writer node.
Before we start, if you are not familiar with Spectra and (or) Snowflake, I would urge you to check out the following links to get started:
Now that we are familiar with the context, let’s begin.
Flow configuration and what nodes we will use
Consider a straightforward use case with two tables – Customer and Nation. I have chosen these tables from Snowflake’s sample data share SNOWFLAKE_SAMPLE_DATA and copied them into my own Database and Schema.
Here’s what the structure of these tables looks like –
Customer
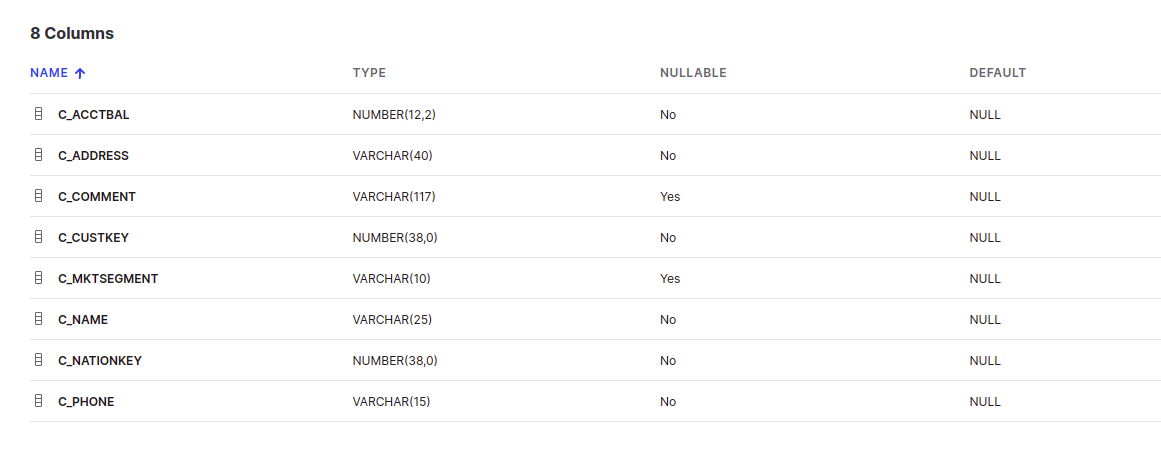
Nation
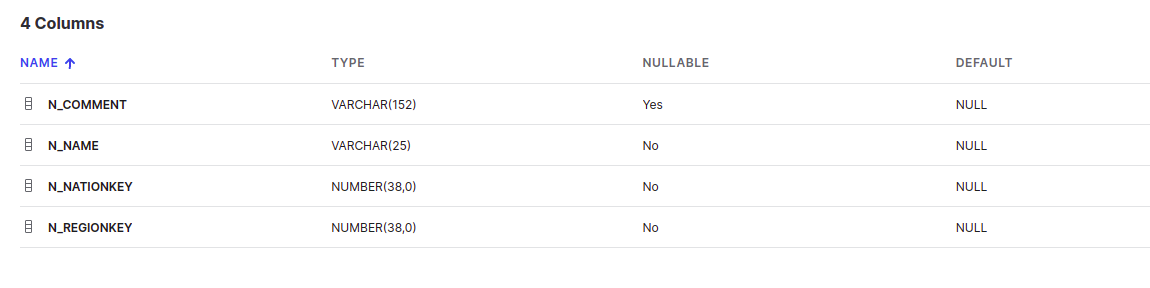
To achieve our use case, we would need to use the following nodes on Spectra
Two Snowflake readers
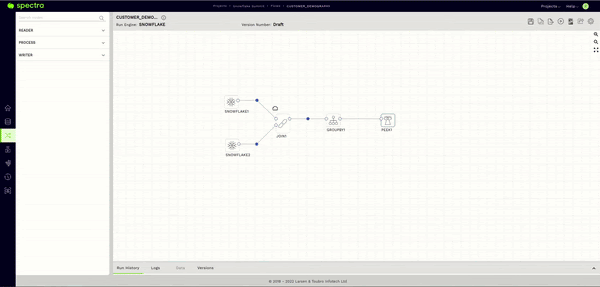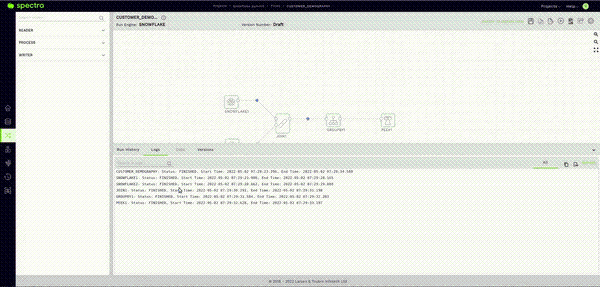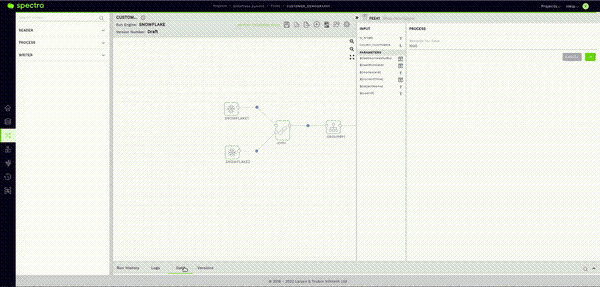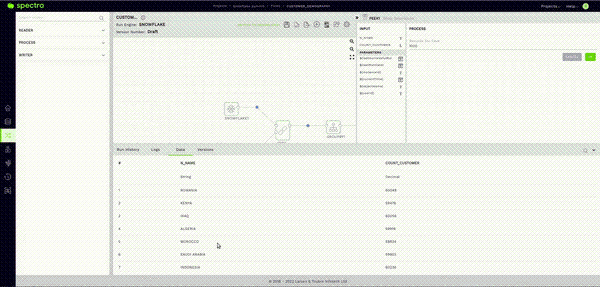
In this case, one reader is for monitoring the Customer Table and the other for the Nation Table. Configuring a reader node and checking its sample data from within Spectra is an effortless process. All you must do is drag a Snowflake reader node into the canvas. It can be found in the left panel under the READER Section.
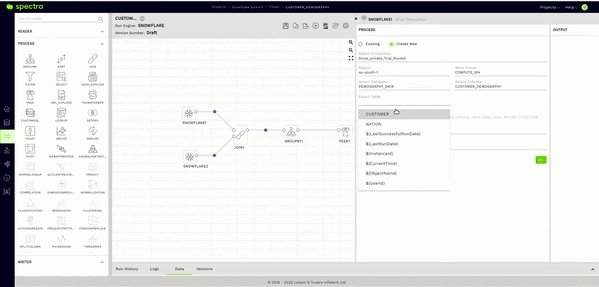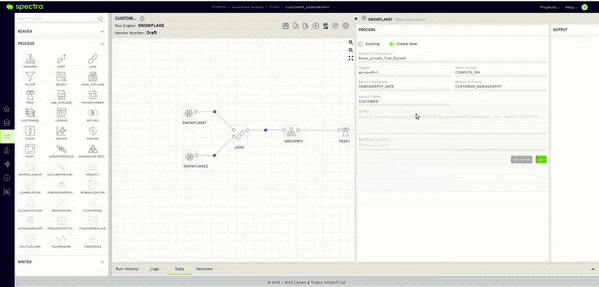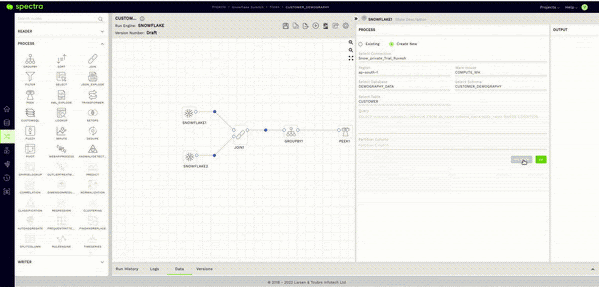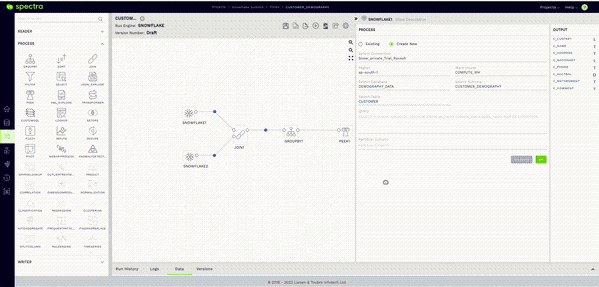
Once on the canvas, the process is as simple as selecting your connection, database, schema, and table. Then, tap on the validate button.
How to see sample data of tables in Spectra
Awesome, we have configured our readers, and now you may be wondering, “How do I know what data is in these tables that I have configured my readers with? Do I have to go to my Snowflake UI to find out?”
The answer is a very reassuring “NO.” This brings me to Spectra’s Sample Data feature. After validating the reader node as seen in the previous step, all you have to do here is click on the Data Tab in the Bottom Panel and give it a few seconds.
This will fetch a sample of the data stored in your Snowflake table within the Spectra UI itself.
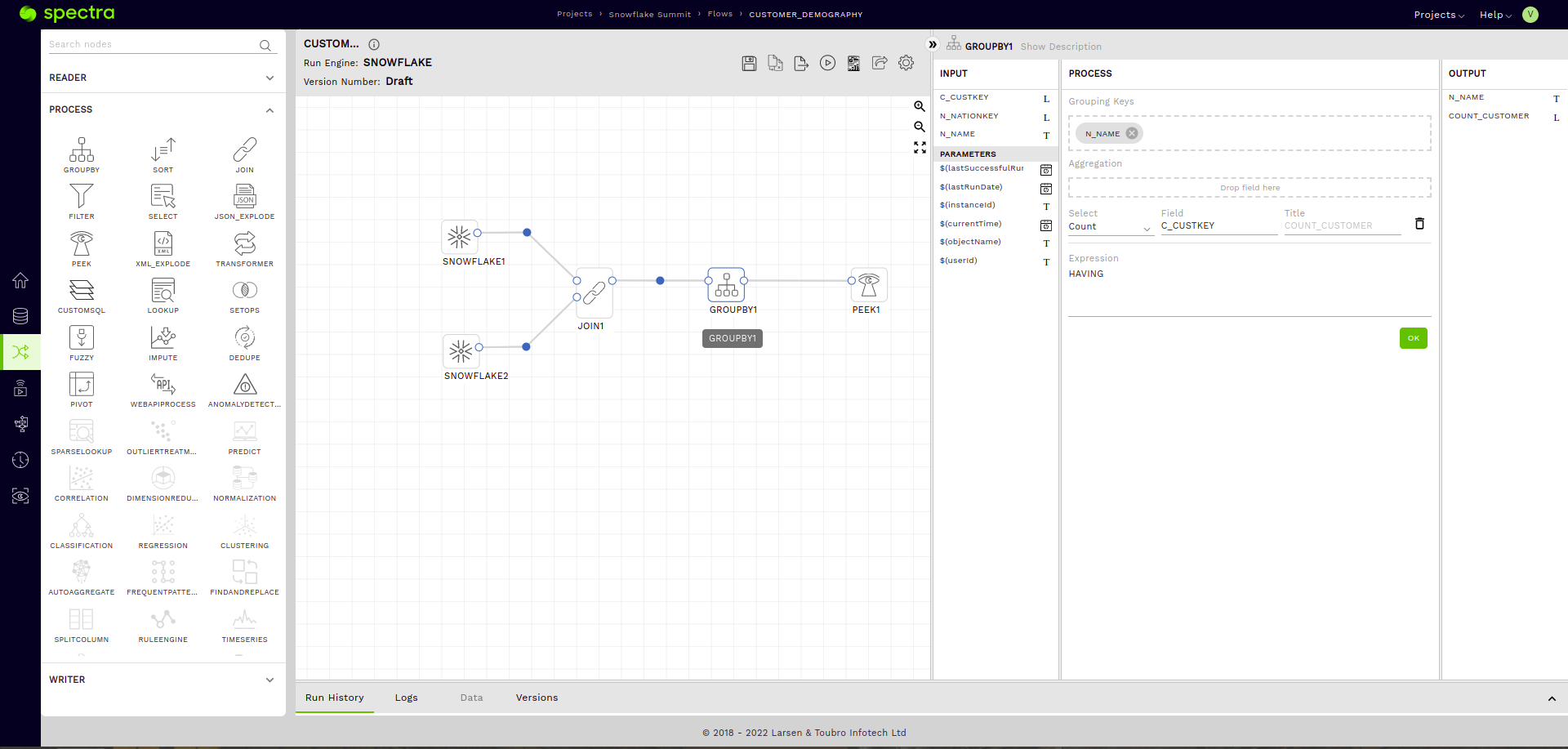
Join node
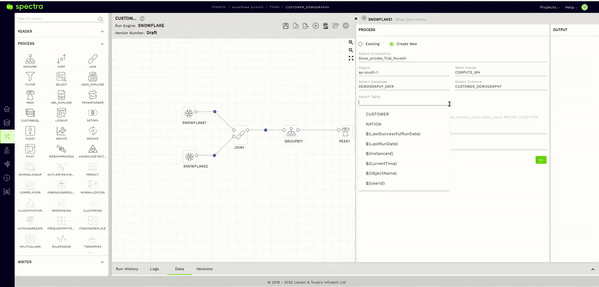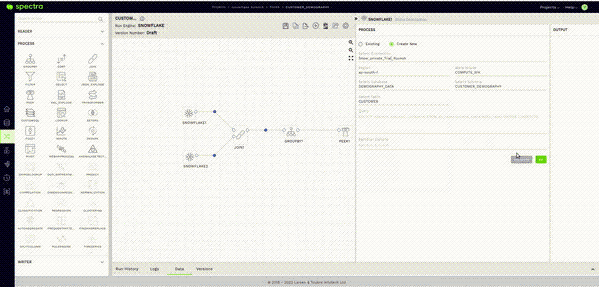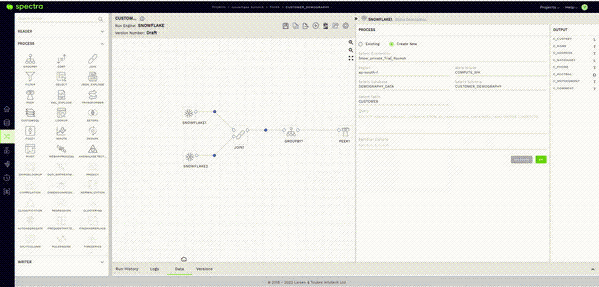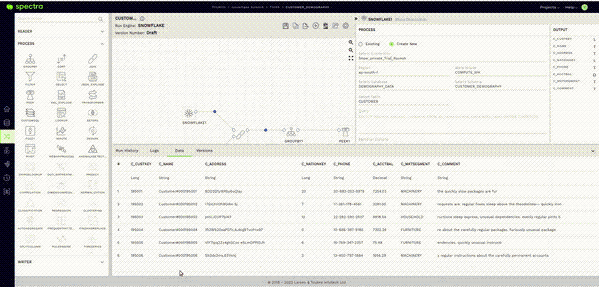
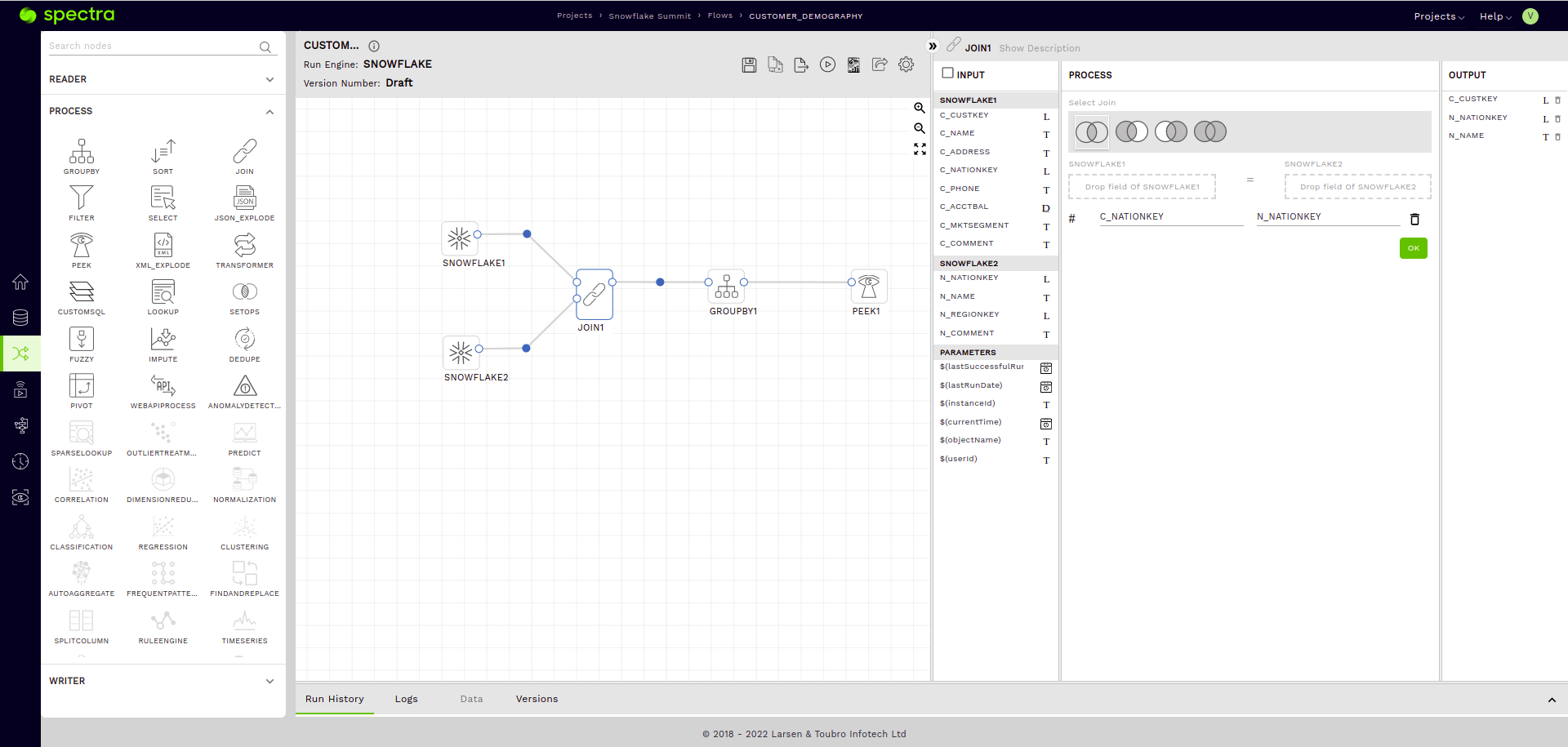
We will add a simple inner join to join the Customer and the Nation table on the NATIONKEY columns (JOIN ON C_NATIONKEY = N_NATIONKEY).
Additionally, from the INPUT section of our Join Node, let’s drag the C_CUSTKEY column under the first Snowflake Reader (corresponding to the Customer Table) and the N_NAME Column under the second Snowflake Reader (corresponding to the Nation Table) into the OUTPUT section of our Join Node.
Group by node
Let’s add a group by node and group the data on the N_NAME (Nation Name Column), and add an aggregation to count the number of customers in each Nation. We use COUNT(C_CUSTKEY) for this in the Aggregation sub-section under the PROCESS section or our Group by Node.