Reading Time: 4 minutes
Reading Time: 4 minutesGlobal advertisers utilize the concept of “Sales Lift” to estimate the increase in sales resulting from a specific advertisement, and to assess the effectiveness of their advertising efforts. This approach enables advertisers to make informed decisions regarding the allocation of advertising budgets, the selection of ad types, and targeting of their ads to maximize impact. However, it is crucial to account for confounding variables and their impact on the success or failure of these ad campaigns.
Confounding variables – demographic factors like age or income – have the potential to influence both advertising and sales figures. Failing to effectively monitor these variables may lead advertisers to incorrectly attribute the increase in sales.
In this use case, we will demonstrate how the Snowflake platform along with Refract can be used in this scenario for data analysis and model training. By understanding how certain confounding variables can predict whether a user will purchase a product, advertisers can make more accurate predictions.
Refract by Fosfor, is built to enable new-age data-to-decision teams; it accelerates and automates the entire Data Science, Artificial Intelligence (AI), and Machine Learning (ML) life cycles, from data discovery to modelling, deployment, and monitoring. Refract addresses the needs and challenges of different user personas by fostering collaboration and making data consumption for decision-making simple and effortless.
Additionally, the Refract platform is employed for hosting and post-production monitoring of the model. To facilitate insights contextualization for business users, we have developed a Streamlit app that allows them to grasp the intricacies of the data and appreciate the benefits. We have tried to keep the solution simple by not predicting the sales lift, but rather just predicting if the user is going to make the purchase given some confounding parameters.We have also ensured that the solution is visually intuitive, so that even non-technical users can understand the data.
Note: This solution is inspired from and built on top of another article written by our strategic technology partner, Snowflake. The article offers an excellent explanation on the dataset that was built and showcases some of the fantastic Snowflake features that were used to build the solution.
Business problem:
Most businesses look to calculate what the sales lift would be or try to understand the probability of sales conversion for a particular user after consuming a targeted advertisement. To keep the problem statement simple, we used only a few of the confounding parameters (age band, marital status, if they saw the ad or not, etc.) to predict if the user would make the purchase. But a few other “non-confounding” parameters were also used to make it more robust, such as the channel and form of advertisement, and other demographical data (like employment details, etc.). Perhaps even a market mix model, can be used in a future version of this solution.
Refract by Fosfor:
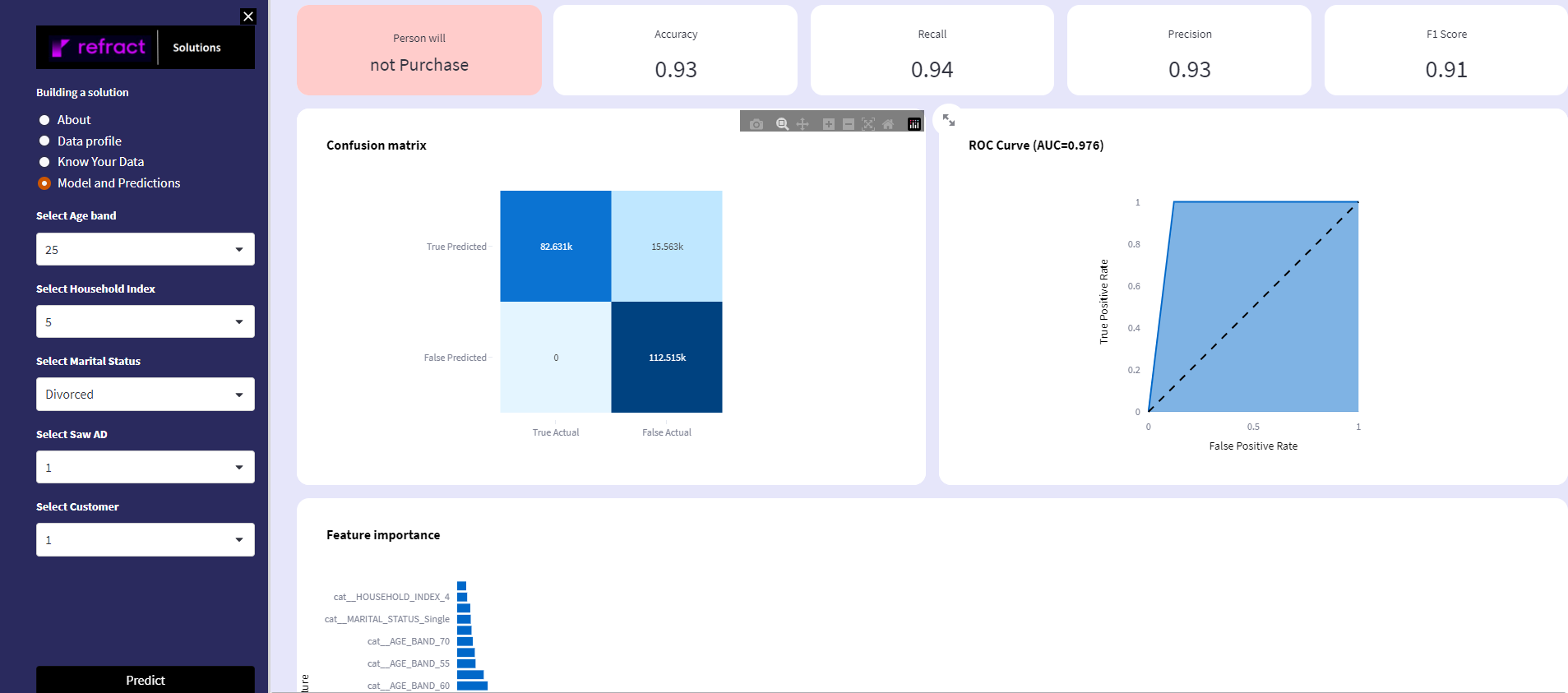
In this example, data manipulation and modeling has been executed on Snowflake, to provide for data security, while Refract provides an integrated platform to track and consume the model performance through a Streamlit app. This app provides a direct UI to consume the model in a what-if type of analysis and understand the data using dynamic visualizations.
Key benefits of the proposed solution:
- Powerful, flexible data science pipelines built through Snowpark for Python
- Quick visualizations of attrition facts & figures through Streamlit (quicker turnaround for everyday visualizations)
- Interactive storytelling with quick app-style deployment of notebooks
The below image is a representation of the solution workflow that illustrates how the Streamlit app is connected and integrated on Refract.
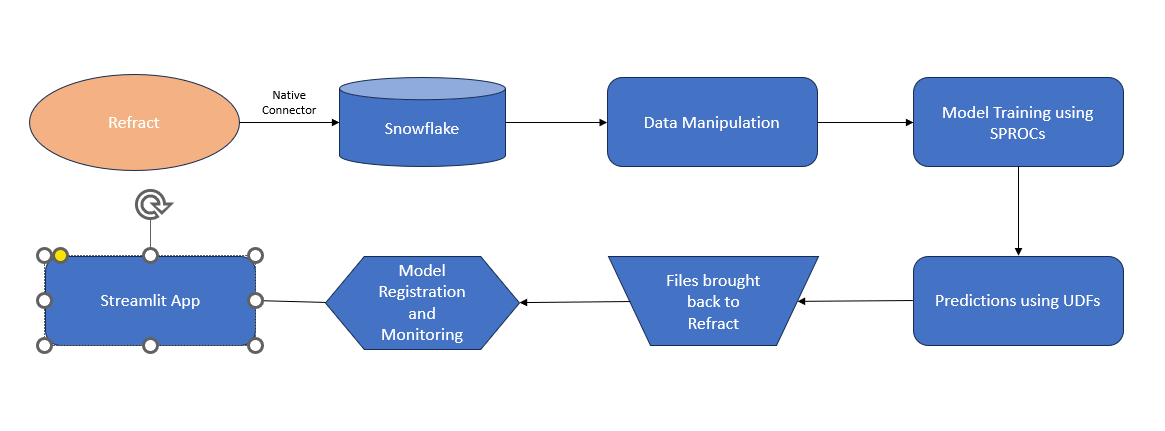
Image 1: Refract solution workflow
The data:
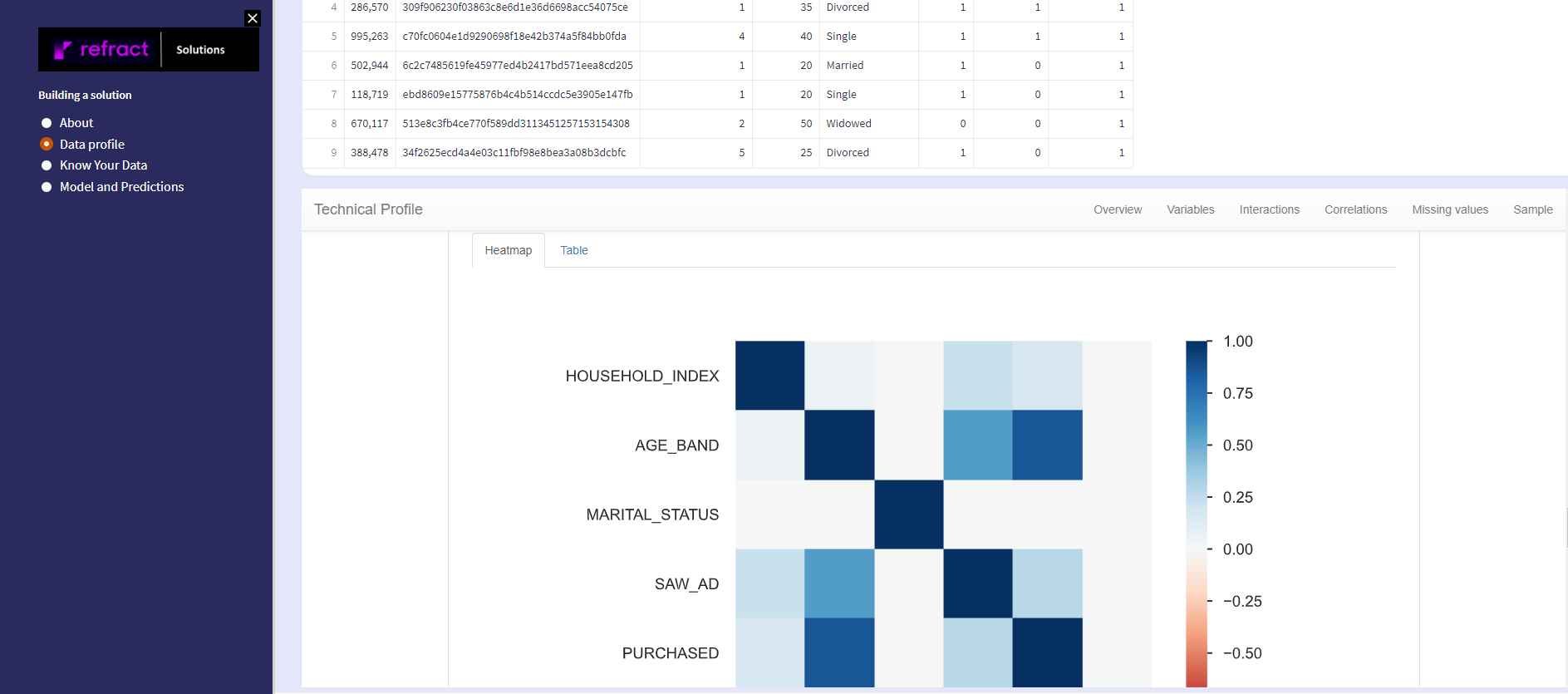
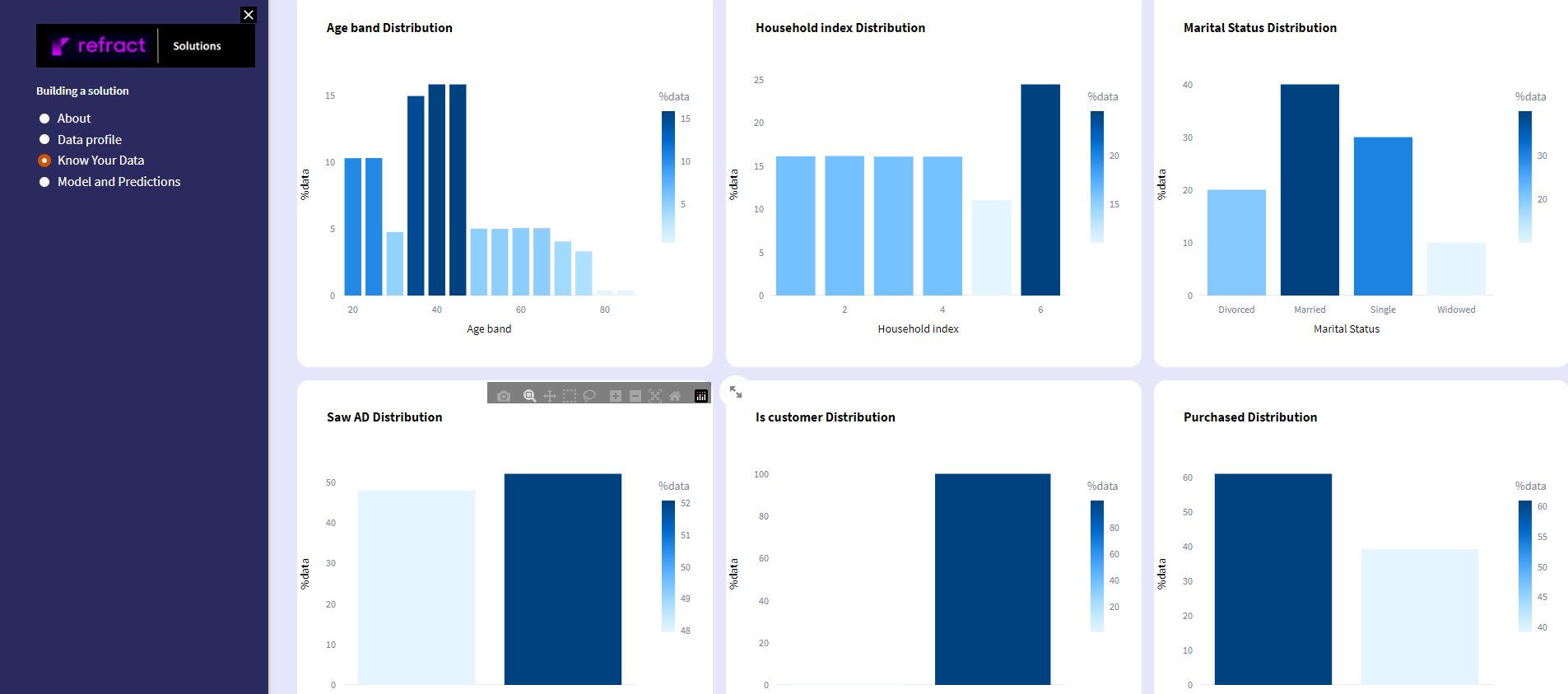
- To understand and to be able to predict user purchase patterns, we have mapped user demographics such as marital status, age band, type of household, etc.
- We also have the details regarding if they are already a customer of the brand
- we tracked the details if the user has watched the ad
- We also mapped which user has purchased the product given the other confounding variables
The process:
Step 1: We have used Refract’s integrated Jupyter notebooks to connect to Snowflake and start a session. As the Snowpark API requires Python 3.8, Refract gives users the option to freely choose the desired version of Python. Refract has pre-created templates catering to a wide area of use cases.
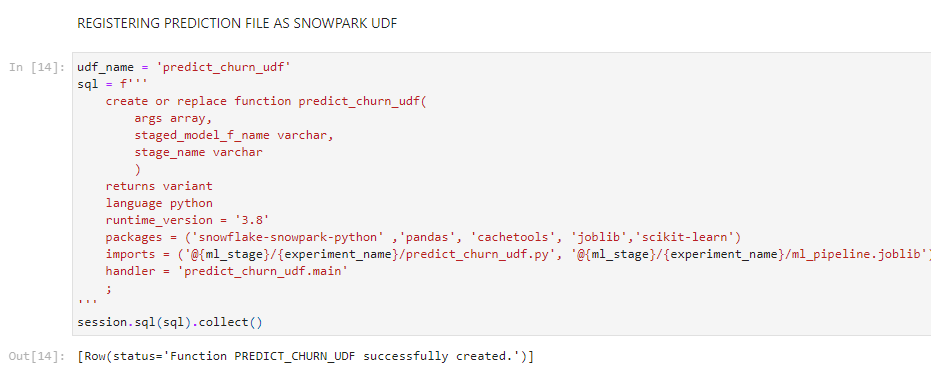
Step 2: We created a data pre-processing pipeline for simple manipulations like missing value imputations, data scaling, and one-hot-encoding, followed by the model training pipeline consisting of Random forest algorithm and grid search for finding the best parameters. This entire code is written in a separate .py file in the form of Python functions, which is then sent to Snowflake stage that you will be using. This training function is then registered as a stored procedure using Snowpark SQL.

Using the above code, you can send any file to your Snowflake stage.
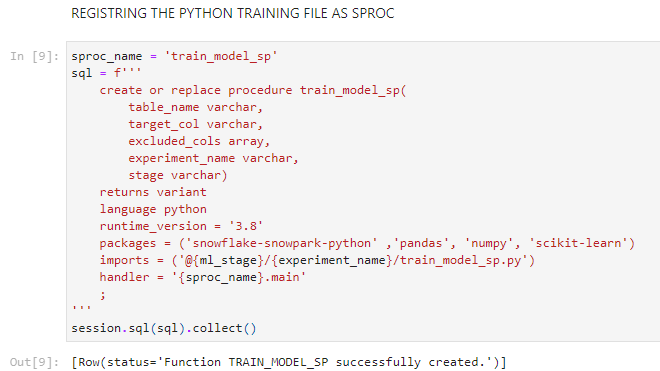
Image 2: Code for registering the model training pipelines as a SPROC (stored procedure) in Snowflake.
The above piece of code will register the model training pipelines as a stored procedure in Snowflake where the training will happen, do remember to mention the Python modules you will be using in your training pipeline, and if your pipeline has multiple functions, specify the main function as the handler of the SPROC.

Image 3: Code for triggering the stored procedure
Using the above code you can trigger the training stored procedure, while mentioning the variables that you don’t want to use in your training.