


 Reading Time: 4 minutes
Reading Time: 4 minutesIntroduction: The rise of open table formats
In the evolving landscape of data management, organizations increasingly seek solutions that foster flexibility, scalability, and openness. Traditional closed data platforms, though functional, often lead to challenges such as vendor lock-in and high costs associated with moving or duplicating data across different systems. This demand for open, interoperable solutions has fuelled the rise of open table formats, and among the most impactful of these formats is Apache Iceberg.
What is Apache Iceberg?
Apache Iceberg is an open-source table format designed to facilitate efficient management and querying of large datasets in data lakes. Unlike traditional formats that rely on complex metadata management systems, Iceberg simplifies data operations by providing a clear abstraction layer over underlying storage systems. This allows users to interact with their data using familiar SQL commands while benefiting from advanced features such as:
- ACID Transactions: Ensuring data consistency and reliability during concurrent read and write operations.
- Schema Evolution: Allowing users to modify table schemas (add, drop, update, or rename) without rewriting existing data files.
- Time Travel: Enabling users to query historical versions of their datasets for auditing or debugging purposes.
- Hidden Partitioning: Simplifying data querying by eliminating the need for users to know the physical layout of data files.
Iceberg’s architecture is built around a rich metadata model that tracks changes to tables without altering the underlying data files. This design not only enhances performance but also provides a seamless experience for users managing large-scale datasets.
What are Iceberg Tables?
Iceberg tables represent a powerful abstraction within the Snowflake Data Cloud context. Snowflake has integrated support for the Apache Iceberg table format, allowing users to leverage the benefits of this open table format while utilizing Snowflake’s robust cloud infrastructure.
Features of Snowflake native Iceberg Tables
- Native Integration: Snowflake’s catalog seamlessly manages Iceberg tables, making it easy for users to create, write, and query them without additional overhead.
- Data Stored in Parquet Files: The actual data for Iceberg tables is stored in Parquet file format, which is optimized for analytical queries. Parquet’s columnar storage structure allows for efficient compression and encoding schemes that improve performance during data retrieval.
- Customer Managed Storage: Both table metadata and data are stored in customer-supplied external cloud storage solutions such as Amazon S3, Google Cloud Storage, or Azure Blob. This ensures that organizations maintain control over their data while benefiting from the scalability and cost-effectiveness of cloud storage.
Iceberg Tables in the Fosfor Decision Cloud (FDC)
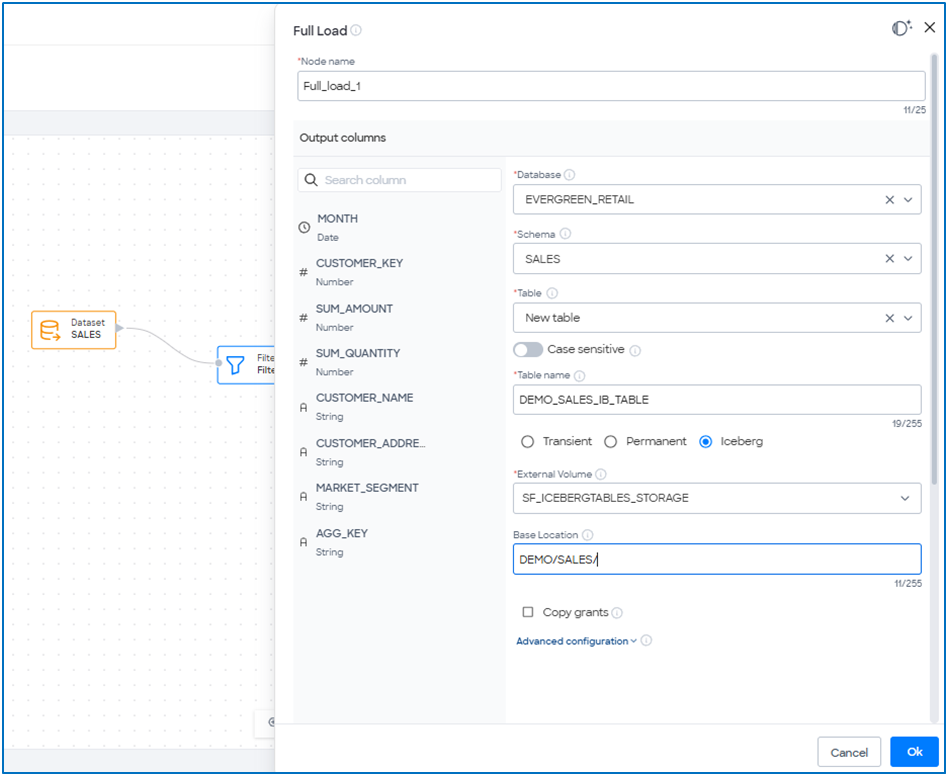
The FDC now supports Iceberg Tables in its Pipeline Studio, allowing the storage and management of curated data in open table format. Pipeline Studio integrates Apache Iceberg tables, allowing users to easily manage and store curated data. The FDC provides robust support for configuring Apache Iceberg tables, facilitating various data loading strategies including Full Load for complete data refresh, Incremental Load for inserting new or updating modified data, and Load SCD-2 for tracking historical changes over time. When setting up a target table in Pipeline Studio, users can select Iceberg as the table type and specify the following parameters:
- External Volume: An External Volume is a Snowflake object that connects directly to external cloud storage, such as AWS S3, Azure Blob Storage, or Google Cloud Storage, to store both Iceberg table data and metadata files. In FDC, users can select an external volume from a dropdown menu, streamlining the connection to external storage.
- Base Location(Optional): The Base Location specifies a directory path within the external volume where Snowflake writes Iceberg table data and metadata files. By default, this field is left blank, meaning data and metadata are stored in the external volume’s base URL. Users can enter a specific directory path to store Iceberg data in a designated location, offering greater control over data organization.
Key features of Iceberg Tables in FDC
- Automated Table Creation: FDC simplifies Iceberg Table creation, reducing manual setup.
- Support for Diverse Data Loads: Enables full load, incremental updates, and SCD Type-2 setup with Iceberg Tables.
- User-Friendly Interface: Provides an intuitive interface for managing Iceberg Tables, making it accessible for both technical and non-technical users.
Why use Iceberg Tables?
1. Interoperability
One of the standout features of Apache Iceberg is its interoperability. By adopting this open table format, organizations can prevent storage lock-in and eliminate the need to move or copy tables between different systems. This flexibility translates into lower compute and storage costs across the overall data stack. Using Iceberg allows businesses to maintain control over their data environments while ensuring compatibility with various processing engines.
2. Storage Flexibility
For many organizations, regulatory requirements dictate where sensitive data can be stored. Apache Iceberg empowers customers to expand the boundaries of their Data Cloud by allowing them to store data within their Virtual Private Cloud (VPC). This capability not only ensures compliance with regulations but also enhances security by keeping sensitive information within controlled environments.
3. Performance Optimization
Organizations facing performance challenges with external tables should consider using Iceberg Tables. These tables reduce the amount of data that needs to be queried and simplify complex queries on top of large datasets. The metadata stored within Iceberg allows for efficient query pruning and data retrieval.
Conclusion: Empowering data freedom with open standards
As organizations increasingly prioritize flexibility, interoperability, and cost-efficiency in their data architectures, the adoption of open table formats like Apache Iceberg has become essential. With Fosfor’s native support for Iceberg Tables, users can now gain access to a simplified, powerful solution for managing and analyzing large datasets.
Apache Iceberg in the Fosfor Decision Cloud offers businesses the agility to manage their data across platforms, meet regulatory requirements, and improve performance—all while reducing costs. By embracing this open standard, organizations can unlock the full potential of their data, driving informed decisions and sustainable growth.








